Interpreted vs. Compiled

It is common to see languages referred to as either compiled or interpreted but what does this actually mean? And why is it important?
Important! I'm gonna be using Linux for the demonstrations in this article but everything should be easy to replicate on windows.
Why the distinction is so important
Making the distinction between compiled and interpreted is important because depending on whether a language is compiled or interpreted, the whole way we interact with it changed and so does its behavior when we run the code.
Why either of them?
Simply put: code in high level programming languages (such as Java, C, C++, Rust, Python, etc) was not meant for computers. Computers only understand binary code. The programming languages we use and love are optimized to be human-friendly: they contain keywords that are mostly from English (or other human languages) and mathematics. This is because writing binary instruction is not only a horrible task but also very inefficient for humans to read and interpret themselves.
As such, because computers cannot understand languages the same way we do, we need a translator, a mediator to sort of "explain" to them what we mean when we write the code in our higher level languages.
Here's when interpreters and compilers come into the picture: they are those translators/mediators. They take the high-level language code you write in, let's say, C++ and "translate" them into a format that our computer understands, binary executable code.
So what is the difference
Compilers
Compilers are computer programs that take a file (or files, but let's not go there) containing code as an input and provide another file containing binary code as an output. The latter can then be executed directly as it's the language that the processor speaks and recognizes.
The compilation step is only done once and the resulting binary code can be executed as many times as we wish.
This is why compiled languages are often so fast, all the slow steps are done at compile time, which allows the runtime to be fast (compile time meaning the time of the compilation runtime meaning the whole duration of time while the program is still in execution).
Speaking of compile time, compilers only catch syntax and semantic errors while other errors such as running out of memory and dereferencing a null pointer are caught at runtime.
Examples of compiled programming languages include: C, C++, C#, Holy C(yes, that's a thing).
Example of running code from a compiled language:
#include <iostream>
int main() {
int a = 4;
int b = 20;
std::cout << a * b << " is the result of 20 * 4" << std::endl;
return 0;
}Now, we have the source code saved into a file called article.cpp but that does not suffice. As I said, the computer doesn't understand this so we can't run it directly.
The next step would be to compile the source code. We will do this using the GCC compiler. GCC or the GNU Compiler Collection is a collection of compilers that support various programming languages. For now we just need the g++ command included in this collection to run our code:
g++ artcile.cpp -o article
This tells gcc to compile the file article.cpp and output the result to another one called simply article (the default behavior would have the output file named simply a).
The resulting file containing binary code can now be run simply by using:
./article
Your terminal should now look like the screenshot above. As you can see, after running the binary file we get the output to the console.
NOTE: I am loosely using English terms here. When I say "translate" from source code to machine code, I don't mean it in the same way human language works. In human language you can translate FROM English TO Romanian and BACK. When it comes to compilation, you can translate FROM (for example) C++ TO machine code but NOT BACK. That's because of the optimizations that the compiler does. It is not impossible but doing that requires very specialized software and lots of work and it's far from being an exact science, especially for languages like C and C++. For languages like Java, you can reverse engineer bytecode to the original source code a lot more easily. That's because most of the optimizations in Java are done at runtime. That's what has allowed Minecraft modding to exist: decompiling Minecraft was a lot easier because it was written in Java.
Interpreters
Interpreters approach the problem of code translation in a bit of a different manner. Instead of taking the source code and making it all at once into executable binary code, interpreters execute the source code instruction by instruction. Roughly speaking, for a piece of (python) code like this:
a = 4
b = 20
print(a * b, " is the result of 4 * 20")
The interpreter would take each instruction line by line, like a = 4, translate it into binary code and then run it immediately. In reality interpretation is much more complex than this but as a though framework, thinking about it in these terms is enough.
Unlike compilers that only do their job once and then they're done, the resulting file can be executed as many times as needed, interpreters need to work (and thus stay in RAM), every time we want to execute source code.
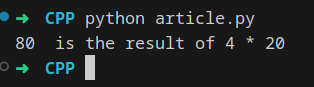
If I want to execute the code above (considering we saved it into a file called article.py) I would need to invoke the Python Interpreter as such:
python article.py
This would produce an output to the terminal directly, without the need to run any other file as interpreters do not produce any output file.
Java: a bit of a different story.
If I just tell you Java code gets executed by something called JVM (Java Virtual Machine) and produces a direct output first of all I would be disingenuous (as this is not the whole story), second of all it would make it look like an interpreted language. It's not just that.
When trying to run Java code, the first step would, of course, be to save the code into a file.
Let's save the following into Article.java :
public class Article {
public static void main(String[] args) {
System.out.println("I just ran some Java code!!");
}
}
Pay attention: the name of the class should be the same as the name of the file.
This file now has to go through the Java Compiler, which gets invoked using the javac command:
javac Article.java
The result we get from the compilation is another file called Article.class.
Now, after compilation, we would be tempted to believe we got some good ole' executable binary code that we can run using ./Article. We would be wrong.
The result of compiling source code with javac is not binary code but Java bytecode. This bytecode is not native to the processor but has to be executed by another program called a JVM (Java Virtual Machine). This is what gives Java power: there are lots of implementations of JVM for lots of different platforms, allowing Java to run on most platforms seamlessly.
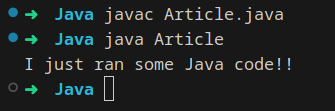
To execute the resulting Article.class bytecode file we will invoke the JVM using:
java Article
Here is the result:
To Summarize:
Compilers get source code as an input and produce binary code as an output which we can run directly on the CPU. Compilation is done once and the resulting file can be executed on demand without touching the compiler again.
Interpreters execute the code line by line, produce no output file and thus need to be used every time we want to run the code.
Java has a mix approach: it has a compiler that translates source code into bytecode which can then be given to the JVM to run and interpret, making Java a hybrid of both approaches.